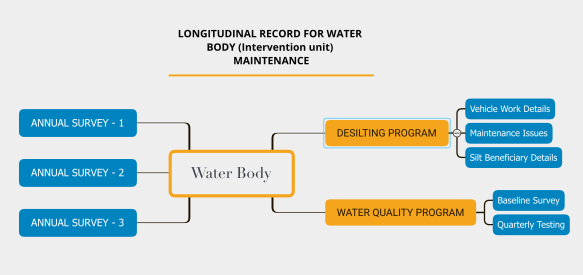
A lot has been written about schemaless databases, but not much on schemaless platforms, on how to make them, how to choose one for your own software project — while there are so many of them around us. CMS, Electronic medical record systems, ERP, CRM, and Forms utilities, to name a few in common domains. Each niche sectors/verticals have such platforms too — like in the social sector there is Avni, CommCare, Bahmni.
What are schemaless platforms?
Schemaless databases allow you to perform data operations, without telling the database about the schema of your data. And they deliver good performance for such use cases.
Schemaless platforms, on the other hand, are designed to tackle the generic end-use cases in a domain and leave the specific parts for the user to define onto the platform. It is the second part (in design and tradeoffs) that this article deals with. At this point, it is important to delineate the term “user”. In most schemaless platforms there is a platform-user who defines their specific data model and an end-user who simply uses that solution. Consider Google Forms which is also a schemaless platform. The person who defines the form is a platform user and the one who fills the data in the form is an end-user. We will refer platform user as a user here.
Unlike Google Forms where the whole platform is about providing a schemaless facility, many products may have a schemaless platform embedded within the product. Such as — a health record management platform may provide features like registration, out-patient, in-patient, laboratory, etc. But within some of these modules, the user can define their own schema for data. For example —there could facility to define forms for different diseases within the out-patient/in-patient modules. The product maker makes a design choice that, it is best to leave some data modeling to the user.
Three types of schemaless platforms
- Products where schemalessness is the defining feature of the product — like Google Forms, ODK, AirTable.
- Products with an embedded schemaless facility in multiple parts of the system— electronic medical records, SalesForce.
- Products that support the definition of custom fields, but they are not very powerful in what they allow — like multiple data types, skip logic, validations, calculated fields, schema migration, etc.
Why are schemaless platforms important?
Schemaless platforms offer an alternative to fully custom software in many scenarios — especially type 2 above. Type 2 schemaless platforms if done right are compelling because they solve a domain-specific problem and at the same time provide the user with the ability to customize as per their needs. We have also written about this here.
This article deals with 1 and 2 — because schemalessness is quite important to these products. We will get into broader technical issues here and go in detail of them in a subsequent article(s) in this series.
Making schemaless platforms
Database for schemaless platforms
Do I need to use NoSQL databases for creating schemaless platforms? Strictly speaking no, because there are ways to achieve schemalessness on relational databases as well. This can be done using one of the following approaches:
- Entity Attribute Value (EAV) — In a nutshell, keep one row per field value. A key column that represents the name of the field and a column for storing the value. This is a good article that explains this pattern.
- Embedded schemaless facility within relational database products. For example support for JSONB within PostgreSQL.
- User-defined database schema — Here the user can specify the schema, using which the platform creates database objects (tables, columns, index, etc) — providing a schema full structure when deployed. This is followed by Strapi and Drupal. One cannot do this if you want to use a single database schema for multiple customers who will all define their schema for themselves.
- Spare columns — The platform provides spare columns in the database tables, where it wants to provide support for user-defined fields. It can choose to represent all data types as a string or provide spare columns for multiple data types. Obviously in-elegant, but clever from a performance perspective, as we will see later. This can be further extended to have spare tables with spare columns.
If you are developing a schemaless platform of type 1 (above) then choosing a NoSQL database may make sense. NoSQL databases are diverse in how to model the data and allow querying of it, unlike relational database products which are quite similar to each other. The choice of the right NoSQL database is out of the scope of this article — but the checklist here applies to them as well.
While for the platform of type 2 you may need to make the decision based on how schemaless vs schema full you are required to be. That is, for what percentage of your product, is the schema known? We cannot prescribe but hope to provide enough details in this series to create a checklist that helps in making a decision.
Management of user schema
While your platform is schemaless, it doesn’t imply that there is no schema. There is almost always a schema. It is with your user. Hence, all schemaless platforms need to provide the ability for the user to define their schema and for the platform to store and serve it. The success of schemaless platforms depends a lot on how simple one makes the process of defining and managing the user schema.
The user-defined schema consists of the same elements that software developers have always dealt with, except they are now in the realm of the users. In relational thinking it would be:
- Entities/Tables
- Fields (with name, data type, behavior)
- Relationships (one-to-one, one-to-many, many-to-many)
Similarly, in document/object modeling, it will be — Aggregates, Objects, and Fields.
Elevating these concepts into the realm of the users where they can use them via a GUI, is a difficult design problem, which has not succeeded at scale. It is tackled in two ways, both of which are tradeoffs:
- Service providers for schemaless platforms—They become the “users” and set up the solution for their customers. Most such products have an ecosystem of “product-implementers”.
- Less featured schemaless platforms make the tradeoff by keeping their platform anemic, by avoiding some features like entity relationships, field-level behavior. These are the most difficult concepts for a non-technical platform user.
Lack of standards — Even though there are many schemaless platforms, this space has lacked standards for defining user schema. Perhaps there are not enough platforms, that will warrant an emergence of standards. The platform users need to learn to define their schema for a new product, every time. XForms is one such standard but it has not seen wider adoption and neither it provides a specification for everything in the schemaless platform world.
Promoting user schema through environments
When you publish a Google Form you are basically deploying the solution from a “development environment” to the “production environment”. All schemaless platforms have to eventually support this process in their product. The more feature-rich user schema the platform supports, the more complex it is to implement the deployment. Products may also be required to support multiple logical environments like development, test, staging, and production — through which the user-schema can be promoted.
At the core of the solution to schema promotion, is the ability to maintain multiple versions of user schema (one per environment) and to merge one version onto the other. Anyone who has written code for merging objects, or version control systems :-), will appreciate the complexity. You can simplify a bit by supporting merge paths in only one direction, i.e. from development to production, and not paths like production to staging (for such scenarios one can simply implement a delete followed by copy).
Technical tradeoffs in schemaless platforms
Schemaless platforms, not surprisingly, are not a silver bullet. There is a price to be paid for going schemaless. Schemaless platforms succeed in scenarios where they keep this cost low. Let us look at the technical issues that emerge with schemaless platforms, to help to make the tradeoff. This section is not about, consumer-targeted platforms like Google Forms, but scenarios where custom development is a real option.
Reporting tools
Relational databases schemas are quite standardized. This allows for reporting tools like Metabase, Tableau, and others to provide numerous features because they can decipher and create an internal model of the user’s schema, automatically by using metadata maintained by databases. With schemaless platforms, we lose these benefits. These reporting tools do not understand EAV, JSONB, and NoSQL very well (standardization could help here too). There are techniques that can be employed to get around some of these issues, as we will see later in this series — but they require additional work. Overall, schemaless data models lead to complex queries and worse performance comparatively.
Database level checks
The database constraints like foreign-key, unique, not null and custom constraints cannot be taken for granted anymore. Depending on the approach taken one may have to give away one or more of these. For example — in EAV, JSONB you cannot implement null/not null and unique constraints for user-defined fields. In JSONB you cannot do foreign keys as well. You have to handle these in the code but they work less well because:
the database can also be updated directly (via migrations, and data fixes)
database checks are far more efficient
code can have defects in how it implements these checks
Data migration on schema change
In schema full applications, the schema change and its associated re-arrangement of data are handled by the programmers using SQL (with flyway, Liquibase, etc). In schemaless platforms, supporting the change in user schema over time is simpler to implement but performing data migration to the new schema is tricky.
For example — adding a new field is simple. But adding a default value for that field (like column default) is complex to implement in a performant way. Similarly, scenarios like moving a field from one entity to all its children, keep getting more and more complex to implement. Most schemaless platforms shy away from implementing these features because they may have to implement complete SQL via GUI — which is a project in itself. So when required, such problems are resolved by contacting technical support.
Published On: 17-Feb-2020
Author: Vivek Singh
]]>
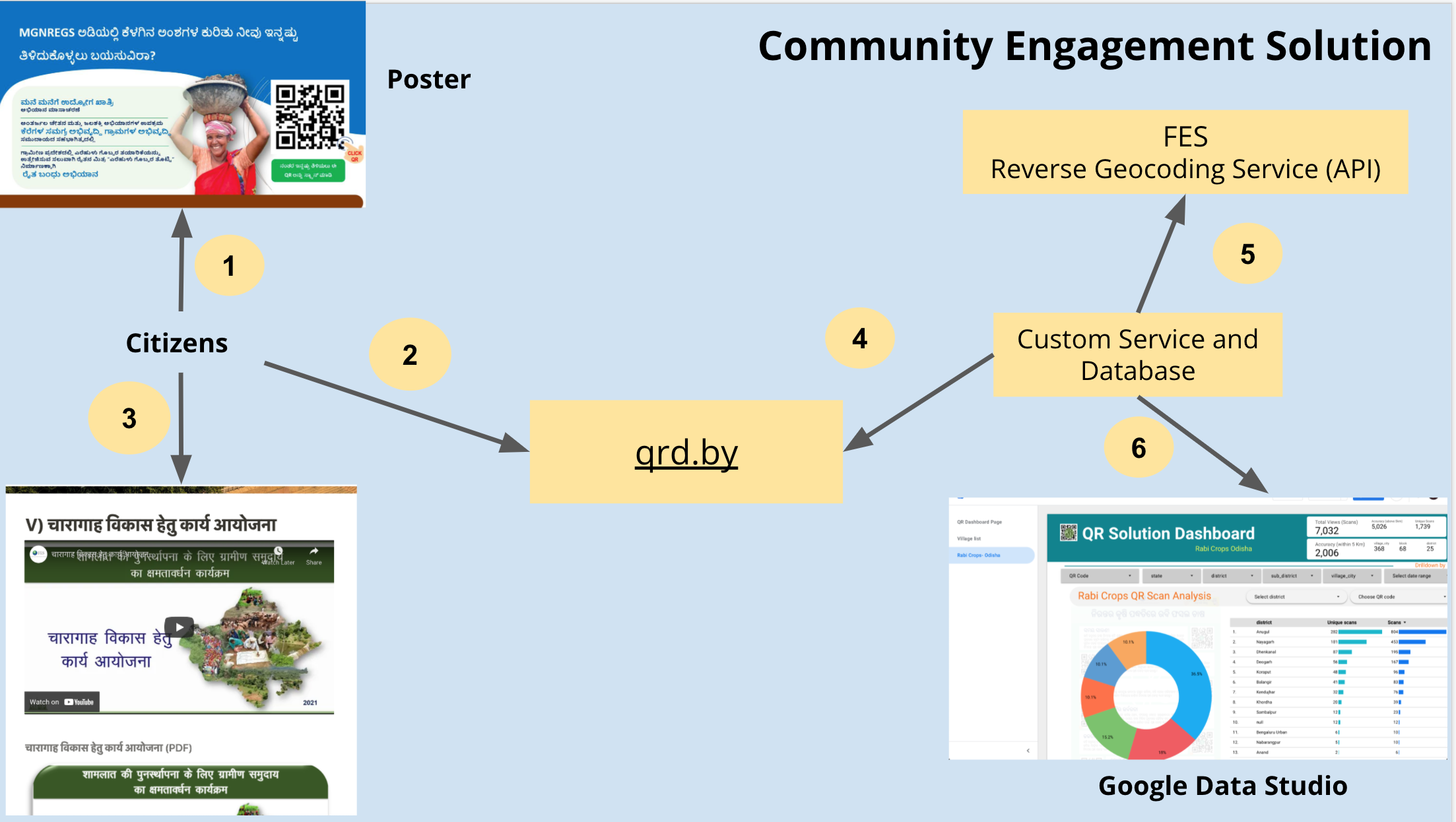



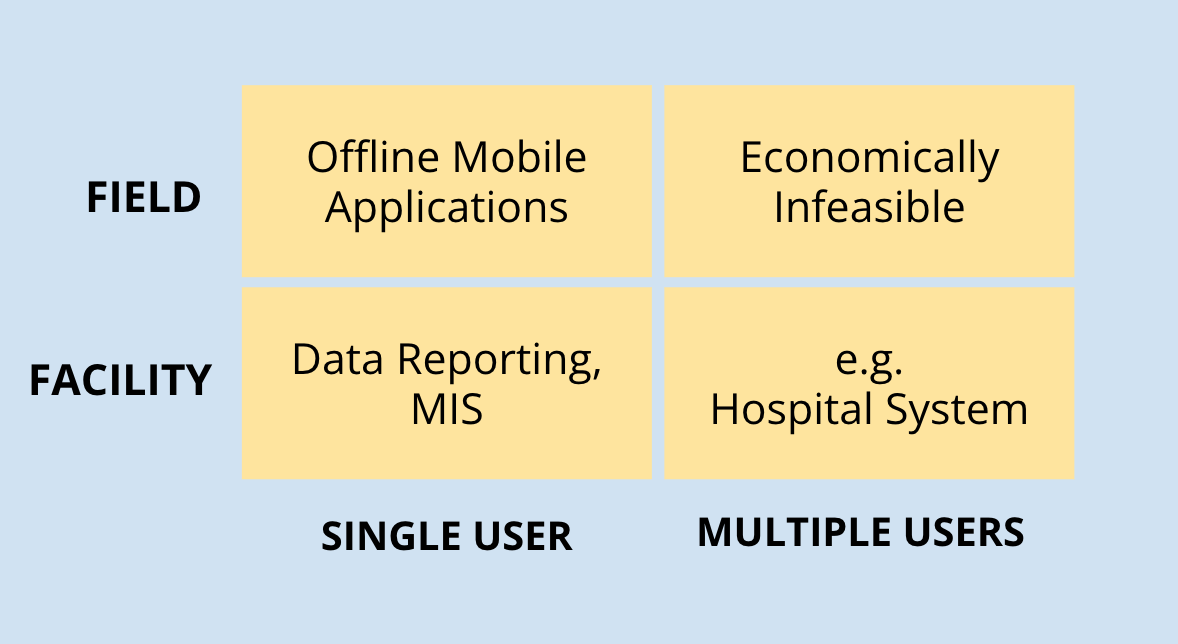

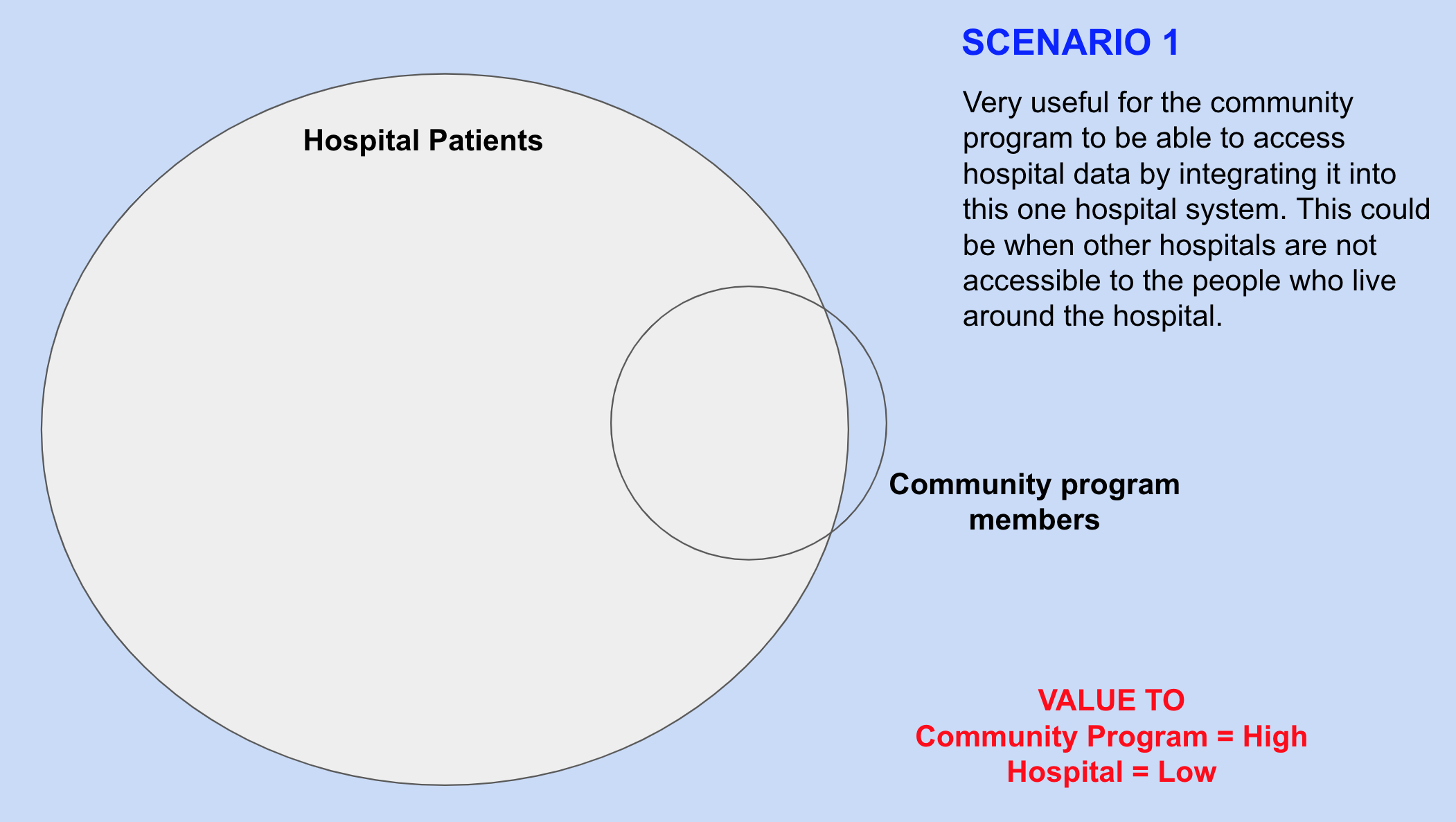
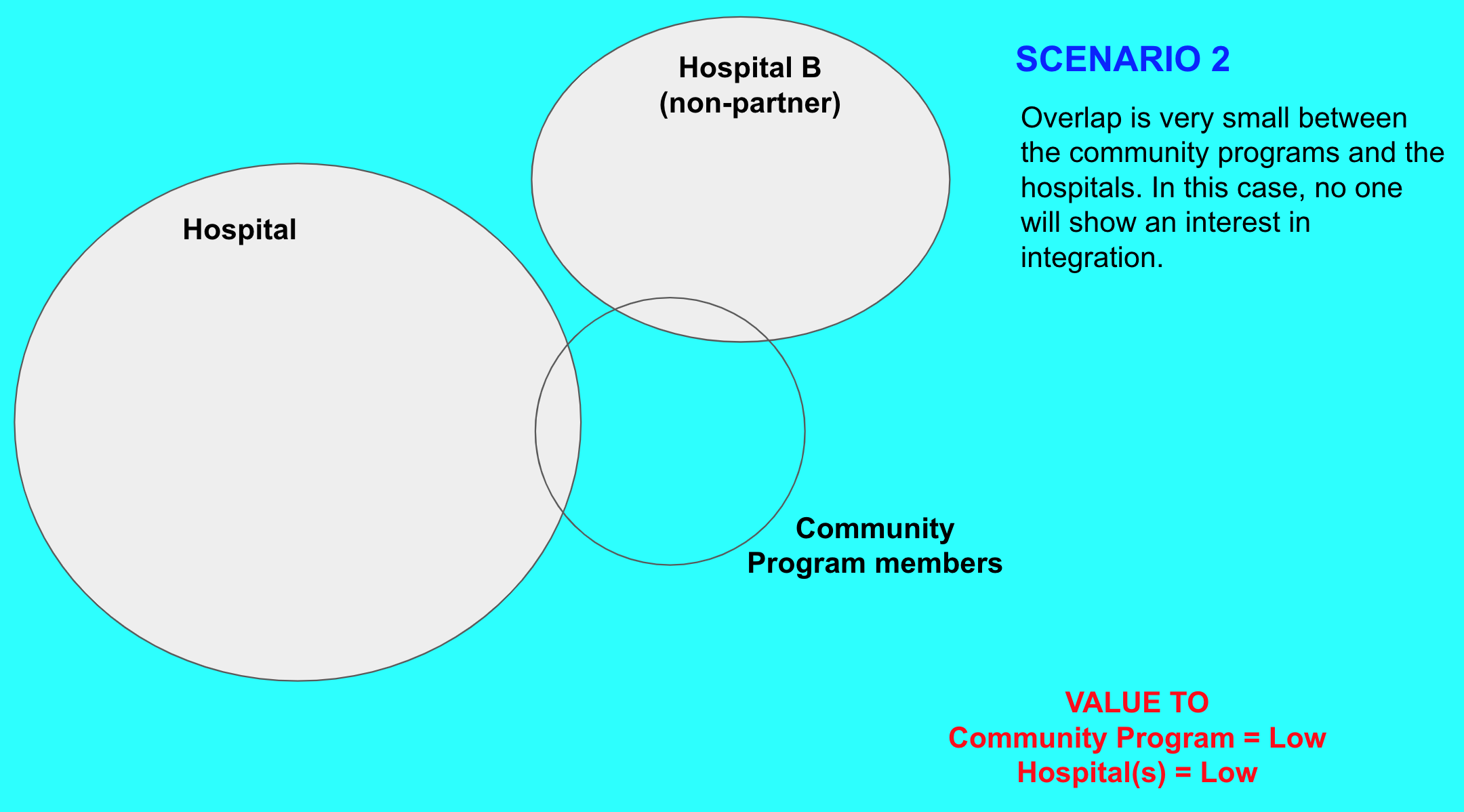
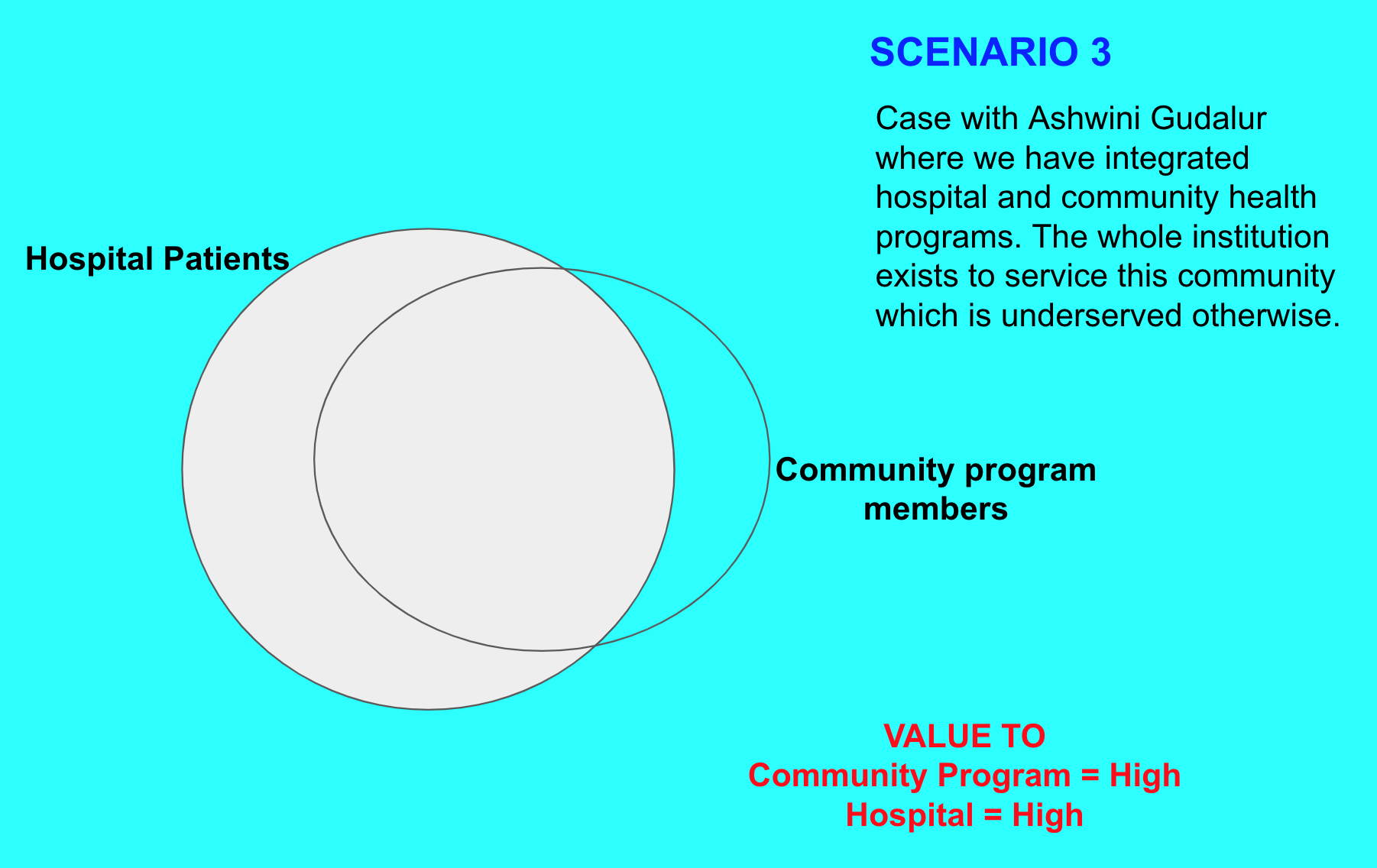

 It is possible that the data entry is done by the field staff themselves at the end of the period
It is possible that the data entry is done by the field staff themselves at the end of the period