
08.04.2024
Nonprofit and Software

05.09.2023
Nonprofit and Software
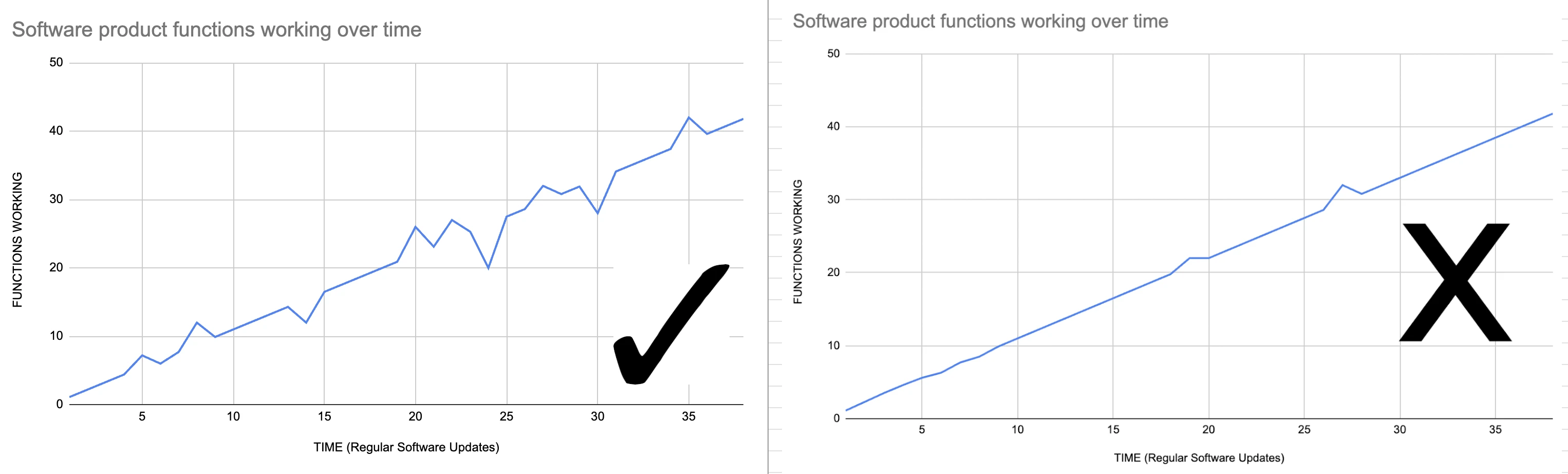
02.06.2023
Software Architecture

05.04.2023
Nonprofit and Software
19.07.2022
Software Architecture
27.05.2022
Nonprofit and Software
23.03.2022
Nonprofit and Software

07.03.2022
Nonprofit and Software
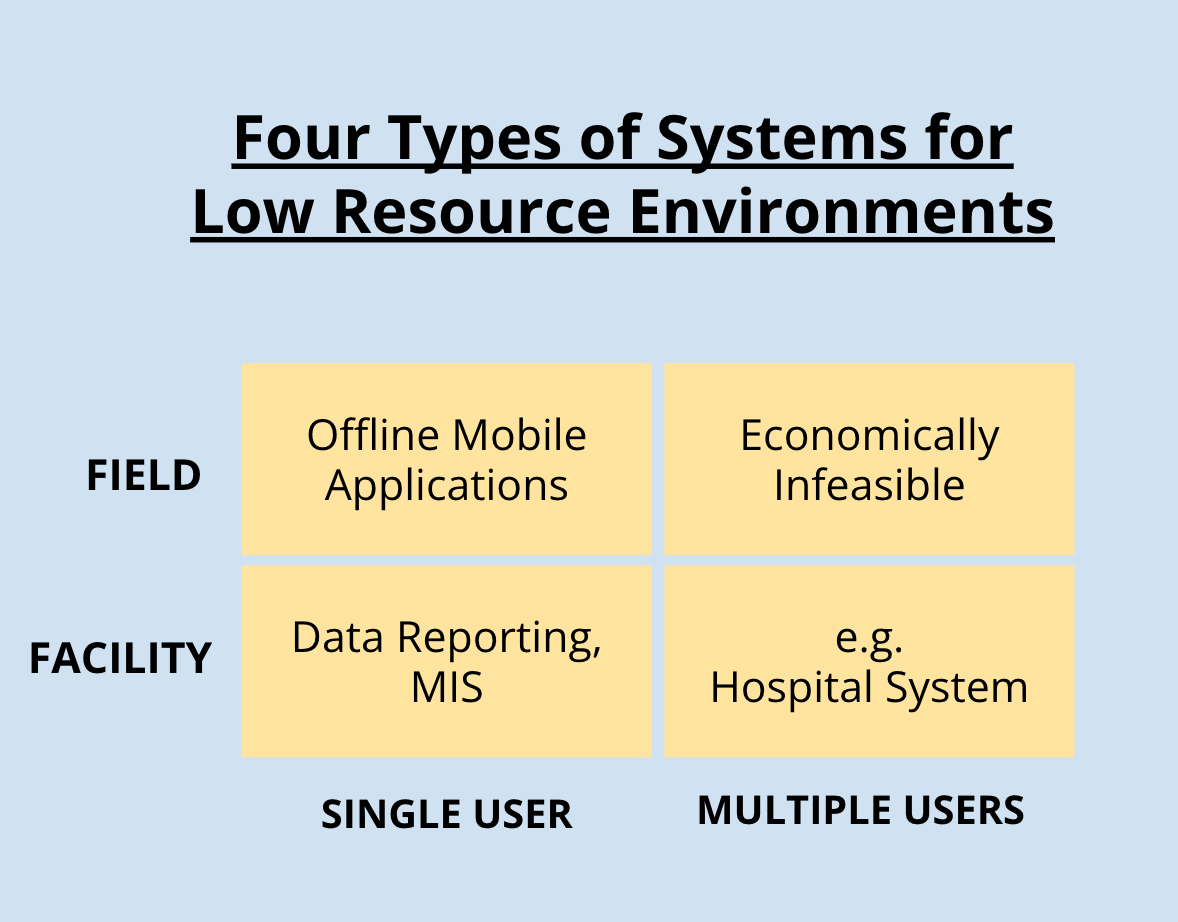
07.12.2021
Nonprofit and Software
22.11.2021
Nonprofit and Software